Google I/O 2023에서 우리는 텍스트 및 임베딩을 위한 Vertex AI PaLM 2 Foundation 모델을 정식 출시하고 새로운 모달리티(코드용 Codey, 이미지용 Imagen, 음성용 Chirp)으로 확장하였습니다. 또한 Foundation 모델을 활용하고 조정(Tune)하는 새로운 방법을 발표했습니다. 이러한 모델은 개발자가 안전, 보안 및 개인 정보 보호를 포함하여 기업에서 사용할 수 있는 기능으로 지원되는 강력하면서도 책임 있는 Generative AI 애플리케이션을 구축하는 데 도움이 됩니다.
LangChain은 언어 모델로 구동되는 Generative AI 애플리케이션을 개발하기 위해 등장한 최신 오픈 소스 프레임워크입니다. 언어 모델 작업에 필요한 추상화 및 구성 요소를 쉽게 교체할 수 있습니다. 다른 도구에 대한 다양한 통합과 새로운 기능이 추가되면서 오픈 소스 커뮤니티에서 널리 채택되었습니다. 언어 모델은 사용하기 간단할 수 있지만 보다 복잡한 애플리케이션을 개발할 때 LangChain의 활용은 충분히 가치가 있습니다.
또한, 텍스트 및 채팅을 위한 Vertex AI PaLM 2 Foundation 모델, Vector Store로서의 Vertex AI Embeddings 및 Vertex AI Matching Engine은 공식적으로 LangChain Python SDK와 통합되어 Vertex AI PaLM 모델 기반 애플리케이션 개발이 보다 손쉽게 되었습니다.
이 블로그 게시물에서는 Vertex AI PaLM Text and Embedding API, Matching Engine 및 LangChain을 사용하여 Generative AI 애플리케이션(문서 기반 Q&A)을 구축하는 방법을 보여줍니다.
Generative Application 구축
대규모 언어 모델(LLM)은 최근 몇 년 동안 상당히 발전했으며 이제 인간의 언어를 합리적인 정도로 이해하고 추론할 수 있습니다. 효과적인 Generative AI 애플리케이션을 구축하려면 LLM이 외부 시스템과 상호 작용할 수 있도록 하는 것이 중요합니다. 이를 통해 모델은 데이터를 인식하고 에이전트가 됩니다. 즉, 데이터를 이해하고 추론하고 사용하여 의미 있는 방식으로 조치를 취할 수 있습니다. 외부 시스템은 공개 데이터 코퍼스(Corpus), 비공개 지식 저장소(Knowledge base), 데이터베이스, 애플리케이션, API 또는 Google 검색을 통한 공개 인터넷 액세스일 수 있습니다.
다음은 LLM이 외부 시스템에서 활용될 수 있는 몇 가지 패턴입니다.
- 자연어를 SQL로 변환, 데이터베이스에서 SQL 실행, 결과 분석 및 제시
- 사용자 쿼리를 기반으로 외부 웹후크 또는 API 호출
- 여러 모델의 출력을 합성하거나 모델을 특정 순서로 연결

그림 1: 외부 시스템과 연계하여 LLM을 활용하는 패턴
이러한 호출을 연결하고 조정하는 것이 사소해 보일 수 있지만 다양한 데이터 커넥터 또는 모델에 대해 연계(글루) 코드를 반복해서 작성하는 것은 일상적인 작업이 됩니다. 그것이 LangChain이 활용될 수 있는 곳입니다!
그림 2: Vertex AI 및 LangChain으로 Generative AI 애플리케이션 구축
LangChain 구성 요소의 모듈식 구현과 이러한 구성 요소를 결합하는 공통 패턴을 통해 언어 모델을 기반으로 복잡한 응용 프로그램을 보다 쉽게 구축할 수 있습니다. LangChain은 이러한 모델이 데이터 소스 및 시스템에 연결되어 손쉽게 서비스되도록 합니다.
- Components는 문서, 데이터베이스, 애플리케이션, API와 같은 외부 데이터를 언어 모델로 가져오는 추상화입니다.
- Agents를 사용하면 언어 모델이 환경과 통신할 수 있으며, 여기서 모델은 다음에 수행할 작업을 결정합니다.
LangChain과 Vertex AI PaLM 2 기반 모델 및 Vertex AI Matching Engine의 통합을 통해 이제 Vertex AI PaLM 2 기반 모델의 성능과 LangChain의 사용 편의성 및 유연성을 결합하여 Generative AI 애플리케이션을 손쉽게 개발할 수 있습니다.
LangChain 개념 소개
LangChain 프레임워크와 알아야 할 개념에 대해 간단히 살펴보겠습니다. LangChain은 언어 모델 애플리케이션을 만드는 데 사용할 수 있는 다양한 모듈을 제공합니다. 이러한 모듈을 결합하여 더 복잡한 응용 프로그램을 만들거나 더 간단한 응용 프로그램을 위해 개별적으로 사용할 수 있습니다.
그림 3: LangChain 개념
- Models은 다양한 유형의 AI 모델에 대한 인터페이스를 제공하는 LangChain의 빌딩 블록입니다. LLM(Large Language Models), 채팅 및 텍스트 임베딩 모델이 지원됩니다.
- Prompts는 일반적으로 모델에(여러 요소로 구성되는) 대한 입력을 나타냅니다. LangChain은 프롬프트 템플릿, 예제 선택기 및 출력 파서와 같이 프롬프트를 쉽게 구성하고 작업할 수 있는 인터페이스를 제공합니다.
- Memory는 단기 또는 장기 대화 중에 메시지를 저장하고 검색하기 위한 구조를 제공합니다.
- Indexes는 문서를 구성하는 방법을 제공하여 LLM이 문서와 상호 작용하는 데 도움이 됩니다. LangChain은 문서를 로드하는 문서 로더, 문서를 더 작은 청크로 분할하는 텍스트 분할기, 문서를 임베딩으로 저장하는 벡터 저장소, 관련 문서를 가져오는 검색기를 제공합니다.
- Chains을 사용하면 특정 순서로 모듈식 구성 요소(또는 다른 체인)를 결합하여 작업을 완료할 수 있습니다.
- Agents는 LLM이 도구를 통해 외부 시스템과 통신하고 주어진 작업을 완료하기 위한 최선의 행동 과정을 관찰하고 결정할 수 있도록 하는 LangChain의 강력한 구조입니다.
다음은 Vertex AI PaLM API 및 LangChain 통합을 보여주는 코드 스니펫입니다.
- 언어 작업을 위한 Vertex AI PaLM API for Text가 포함된 LangChain LLM
from langchain.llms import VertexAI
llm = VertexAI(model_name='text-bison@001')
question = "What day comes after Friday?"
llm(question)
- 멀티턴 채팅을 위한 채팅용 Vertex AI PaLM API를 사용한 LangChain 채팅 모델
from langchain.chat_models import ChatVertexAI
chat = ChatVertexAI()
chat([SystemMessage(content="You are an AI Assistant suggests what to eat"),
HumanMessage(content="I like tomatoes, what should I eat?")])
- Vertex AI 텍스트 임베딩 API를 사용한 LangChain 텍스트 임베딩 모델
from langchain.embeddings import VertexAIEmbeddings
embeddings = VertexAIEmbeddings()
text = "Embeddings are a way of data representation."
text_embedding = embeddings.embed_query(text)자세한 내용은 LangChain 개념 가이드를 참조하십시오.
"Ask Your Documents": Vertex AI PaLM API, Matching Engine 및 LangChain으로 질의 응답 애플리케이션 구축
Google Cloud에서 문서 Q&A 시스템을 구현하는 몇 가지 방법이 있습니다. 즉시 사용 가능한 환경을 위해 Cloud AI의 완전 관리형 엔터프라이즈 검색 솔루션을 사용하여 몇 분 만에 시작하고 Google의 독점 검색 기술로 구동되는 검색 엔진을 만들 수 있습니다. 이 섹션에서는 Vertex AI 스택에서 제공되는 구성 요소를 사용하여 "자신만의" Q&A 시스템을 구축할 수 있는 방법을 보여줍니다.
그림 4: Ask Your Documents: Vertex AI PaLM API, Matching Engine 및 LangChain으로 QA 시스템 구축
LLM은 양적으로나 질적으로 크게 개선되었습니다. 이 척도는 LLM이 질문 답변, 요약, 콘텐츠 생성과 같은 이러한 능력에 대해 직접 교육을 받지 않고 단순히 자연어를 이해함으로써 배우는 새로운 능력을 잠금 해제했습니다. 그러나 LLM에는 몇 가지 제약이 있습니다.
- LLM은 대규모 말뭉치에서 오프라인으로 훈련되며 훈련 종료 후 이벤트를 인식하지 못합니다. 예를 들어 2022년까지의 데이터로 훈련된 모델은 오늘의 주가에 대한 정보가 없습니다.
- 학습 데이터에서 LLM이 학습한 지식을 파라메트릭(parametric) 메모리라고 하며 신경 가중치에 저장됩니다. LLM은 파라메트릭 메모리의 쿼리에 응답하지만 대부분의 경우 정보 출처를 알 수 없으며 LLM은 축어적 인용을 제공할 수 없습니다. 우리는 LLM 기반 시스템이 "소스를 인용"하고 출력이 사실에 "접지"(연결)되는 것을 선호합니다.
- LLM은 일반 말뭉치에서 텍스트를 생성하는 데 능숙하지만 기업은 내부의 Knowledge Base에서 텍스트를 생성해야 합니다. AI 어시스턴트는 정확하고 적절한 답변을 제공하기 위해 Knowledge Base를 기반으로 질문에 답해야 합니다.
제약 조건을 해결하기 위한 접근 방식 중 하나는 정보 검색(IR) 메커니즘을 통해 외부 knowledge base에서 검색된 관련 데이터로 LLM에 전송된 프롬프트를 보강하는 것입니다. 프롬프트는 관련 데이터를 질문과 함께 컨텍스트로 사용하고 파라메트릭(매개변수) 메모리 사용을 피하거나 최소화하도록 설계되었으며 외부 knowledge base를 비매개변수 메모리라고 합니다. 이 접근 방식을 RAG(retrieval Augmented Generation)라고 하며 QA 작업의 맥락에서 Generative QA라고도 합니다. 이러한 유형의 접근 방식은 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 논문에서 소개되었습니다.
이 섹션에서는 비공개 문서 모음을 기반으로 질문에 응답하고 관련 문서에 참조를 추가하는 RAG 패턴 기반 QA 시스템을 구축하는 방법을 보여줍니다. Google에서 게시한 연구 논문 샘플을 비공개 문서 코퍼스로 사용하고 이에 대한 QA를 실행합니다. GitHub 리포지토리에서 함께 제공되는 코드를 찾을 수 있습니다.
RAG 기반 아키텍처에는 (1) 검색기 및 (2) 생성기의 두 가지 주요 구성 요소가 있습니다.
그림 5: 검색기반 생성 패턴 (Retrieval augmented generation)
- 검색기(Retriever): Knowledge base는 IR 메커니즘과 통합되어 사용자의 쿼리를 기반으로 문서에서 관련 정보(snippets)를 검색합니다. Knowledge base는 자체 문서 코퍼스, 데이터베이스 또는 API일 수 있습니다. Retriever는 키워드, TF-IDF, BM25, 퍼지 매칭 등과 같은 용어 기반 검색을 사용하여 구현할 수 있습니다. 또 다른 접근 방식은 조밀한 임베딩을 기반으로 하는 벡터 검색을 사용하는 것입니다. 이 검색은 텍스트에서 의미론적으로 풍부한 정보를 캡처하여 훨씬 더 효율적인 정보 검색으로 이어집니다. IR 메커니즘에서 검색된 관련 정보(snippets)는 다음 단계인 Generator에 "컨텍스트"로 전달됩니다.
- 생성기(Generator): 컨텍스트(Knowledge base의 관련 snippets)가 LLM으로 전달되어 소스 문서에 기초한 올바른 형식의 응답을 생성합니다.
이 접근 방식은 쿼리에 응답하기 위해 knowledge base에서 관련 정보만 추출하여 LLM 메모리의 제한을 피하고 환각과 같은 예기치 않은 동작을 완화합니다. 또 다른 이점은 최신 문서와 임베딩 표현을 추가하여 지식 기반을 최신 상태로 유지할 수 있다는 것입니다. 이렇게 하면 귀하의 응답이 항상 근거 있고 정확하며 관련성이 있는지 확인할 수 있습니다.
High Level Architecture
검색기반 생성(retrieval augmented generation) 패턴의 아키텍처는 다음 Vertex AI 스택을 사용하여 Google Cloud에서 구축 가능합니다.
- 텍스트용 Vertex AI 임베딩: 최대 3072 토큰 길이의 문서 또는 텍스트가 주어지면 API는 모든 벡터 저장소에 추가할 수 있는 768차원 텍스트 임베딩(부동 소수점 벡터)을 생성합니다.
- Vertex AI Matching Engine: 색인에 임베딩을 추가하고 매우 빠른 벡터 검색을 위해 키 임베딩으로 검색 쿼리를 실행할 수 있는 Google Cloud의 완전 관리형 벡터 저장소입니다. Vertex AI Matching Engine은 10억 개 이상의 벡터에서 가장 유사한 벡터를 찾습니다. 로컬에서 실행되는 벡터 저장소와 달리 Matching Engine은 규모(수백만 및 수십억 벡터)에 최적화되어 있으며 Enterprise급 벡터 저장소입니다.
텍스트용 Vertex AI PaLM API: API를 사용하면 컨텍스트 정보, 지침, 예제 및 기타 유형의 텍스트 콘텐츠를 추가하여 프롬프트를 구성하고 텍스트 분류, 요약, 질문 답변 등과 같은 모든 작업에 사용할 수 있습니다.
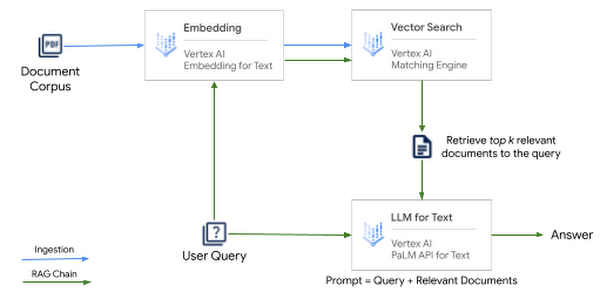
그림 6: RAG 패턴으로 QA 시스템을 구축하는 아키텍처
LangChain은 Vertex AI PaLM API for Text, Vertex AI Embeddings 및 Matching Engine과 통합된 검색 QA 체인을 사용하여 이러한 모든 구성 요소를 원활하게 조정합니다. 아이디어는 질문이 주어지면 다음과 같습니다.
- 먼저 검색 단계를 수행하여 관련 문서를 가져옵니다.
- 그런 다음 원래 질문과 함께 관련 문서를 LLM에 공급하고 응답을 생성하도록 합니다.
문서를 쿼리하기 전에 먼저 검색 가능한 형식의 문서가 있어야 합니다. 크게 두 단계가 있습니다.
- 쿼리 가능한 형식으로 문서 수집 및
- 검색기반 생성(Retrieval augmented generation) 체인
LangChain은 문서 로더, 검색기 및 체인의 형태로 유연한 추상화를 제공하여 단 몇 줄의 코드로 이러한 단계를 구현합니다. 다음은 각 단계의 상위 수준 흐름입니다.
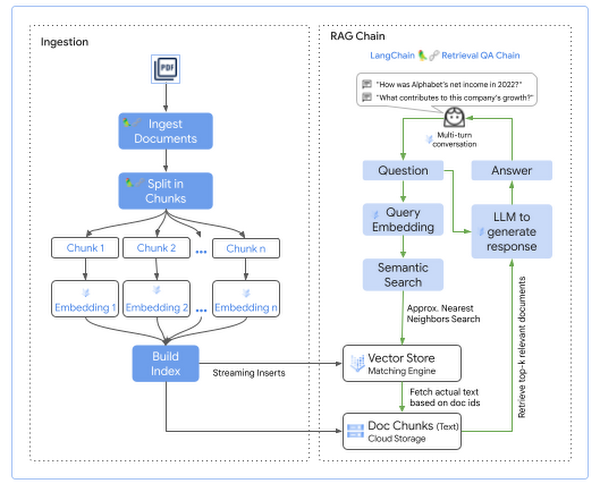
그림 7: RAG 패턴을 사용하여 LangChain 및 Vertex AI로 QA 시스템 구현
구현(Implementation)
초기 설정으로 Matching Engine Index를 생성후 Index Endpoint에 배포하는것으로 문서를 수집하고 인덱스를 쿼리하여 가장 유사한 정보를 응답받을 수 있습니다.
- Matching Engine Index는 문서를 인덱스에 추가/업데이트하거나 삭제하기 위해 스트리밍 인덱스 업데이트로 생성됩니다. 스트리밍 업데이트를 사용하면 몇 초 내에 인덱스를 업데이트하고 쿼리할 수 있습니다.
- Matching Engine Index Endpoint는 퍼블릭 엔드포인트 또는 프라이빗 엔드포인트로 배포할 수 있습니다.
수집(Ingest) 단계에서 문서는 말뭉치(Corpus)에서 임베딩으로 변환되고 나중에 시맨틱 검색을 사용하여 쿼리할 수 있도록 Matching Engine Index에 추가됩니다. 단계는 다음과 같습니다.
- Cloud Storage에 저장된 knowledge base에서 문서 읽기
- 문서의 관련 부분을 프롬프트에 대한 컨텍스트로 포함하도록 각 문서를 분할합니다. 일반적으로 이러한 청크(chunk) 중 여러 개를 컨텍스트로 전달하고 LLM의 컨텍스트에 맞도록 각 청크의 크기를 조정합니다.
- 각 문서 청크(chunk)에 대해:
LangChain은 몇 줄의 코드로 이러한 단계를 수행할 수 있는 유연한 구성 요소를 제공합니다. 다음은 수집 문서에 대한 코드 스니펫입니다.
from langchain.embeddings import VertexAIEmbeddings
from langchain.document_loaders import GCSFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import MatchingEngine
# Define Text Embeddings model
embedding = VertexAIEmbeddings()
# Define Matching Engine as Vector Store
me = MatchingEngine.from_components(
project_id=PROJECT_ID,
region=ME_REGION,
gcs_bucket_name=f'gs://{ME_BUCKET_NAME}',
embedding=embedding,
index_id=ME_INDEX_ID,
endpoint_id=ME_INDEX_ENDPOINT_ID
)
# Define Cloud Storage file loader to read a document
loader = GCSFileLoader(project_name=PROJECT_ID,
bucket=url.split("/")[2],
blob='/'.join(url.split("/")[3:])
)
# Split document into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
doc_splits = text_splitter.split_documents(document)
# Add embeddings of document chunks to Matching Engine
texts = [doc.page_content for doc in doc_splits]
me.add_texts(texts=texts)다음은 문서를 수집할 때 고려해야 할 몇 가지 사항입니다.
- 문서 청크(chunk) 크기 선택: 문서를 분할할 때 각 청크(chunk)가 LLM의 컨텍스트 길이 내에 맞을 수 있는지 확인하십시오.
- 문서 파서 선택: 문서 내의 콘텐츠 유형에 따라 LangChain 또는 LlamIndex에서 사용할 수 있는 적절한 문서 로더를 선택하거나 사용자 정의 로더를 구축합니다. 예) Document AI 프로세서 사용
검색기반 생성(retrieval augmented generation) 체인에서 Matching Engine은 시맨틱 검색을 사용하여 사용자의 질문에 따라 관련 문서를 검색합니다. 그런 다음 결과 문서는 응답을 생성하기 위해 사용자의 질문과 함께 LLM에 전송되는 프롬프트에 추가 컨텍스트로 추가됩니다. 따라서 LLM에 의해 생성된 응답은 벡터 저장소의 검색 결과에 기초합니다. LLM에 전송되는 최종 명령은 다음과 같을 수 있습니다.
SYSTEM: {system}
=============
{context}
=============
Question: {question}
Helpful Answer:다음은 사용자 쿼리에 대한 응답을 생성하는 단계입니다.
- Vertex AI Embeddings for Text를 사용하여 사용자 쿼리에 대한 임베딩을 생성합니다.
- Matching Engine index를 검색하여 사용자 쿼리의 임베딩을 사용하여 임베딩 공간에서 가장 가까운 k개의 가까운 이웃을 검색합니다.
- 사용자 쿼리에 컨텍스트를 추가하기 위해 Cloud Storage에서 검색된 임베딩의 실제 텍스트를 가져옵니다.
- 검색된 문서를 사용자 쿼리에 컨텍스트로 추가합니다.
- 컨텍스트 향상 쿼리를 LLM에 보내 응답을 생성합니다.
- 문서 소스에 대한 참조와 함께 생성된 응답을 사용자에게 반환합니다.
LangChain은 RetrievalQAChain이라는 편리한 구성 요소를 제공하여 몇 줄의 코드 내에서 이러한 단계를 수행합니다. 다음은 검색기반 생성(retrieval augmented generation)을 위한 코드 스니펫입니다.
from langchain.chains import RetrievalQA
from langchain.llms import VertexAI
# Define Matching Engine as Vector Store
me = MatchingEngine.from_components(
project_id=PROJECT_ID,
region=ME_REGION,
gcs_bucket_name=f'gs://{ME_BUCKET_NAME}',
embedding=embedding,
index_id=ME_INDEX_ID,
endpoint_id=ME_INDEX_ENDPOINT_ID
)
# Expose Matching Engine index as a retriever interface
retriever = me.as_retriever(
search_type="similarity",
search_kwargs={"k":NUMBER_OF_RESULTS})
# Define LLM to generate response
llm = VertexAI(model_name='text-bison@001', max_output_tokens=512, temperature=0.2)
# Create QA chain to respond to user query along with source documents
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
# Run QA chain
result = qa({"query": query})검색기반 생성(retrieval augmented generation) 체인에는 몇 가지 고려 사항이 있습니다.
- 문서 청크(Chunk)의 길이 및 검색 결과 수는 응답의 비용, 성능 및 정확성에 영향을 미칩니다. 더 긴 문서 청크는 더 적은 수의 검색 결과가 컨텍스트에 추가될 수 있음을 의미하며 이는 응답 품질에 영향을 미칠 수 있습니다. 응답의 비용은 컨텍스트의 입력 토큰 수에 따라 증가하므로 응답을 생성할 때 포함할 검색 결과 수를 고려하는 것이 중요합니다.
- 체인 유형 선택: 관련 문서를 컨텍스트의 일부로 LLM에 전달하는 방법을 고려하는 것이 중요합니다. LangChain은 스터핑(stuffing), map-reduce 및 refine와 같은 다양한 방법을 제공합니다. 스터핑(stuffing)은 모든 관련 문서를 사용자의 쿼리와 함께 프롬프트에 채우는 가장 간단한 방법입니다.
말뭉치(Corpus)와 관련된 질문을 살펴보겠습니다.
Query: What are video localized narratives?
....................................................
Response: Video Localized Narratives (VidLNs) are a new form of multimodal video annotations connecting vision and language.
....................................................
References:
[REFERENCE #0]
Matching Score: 0.7975
Document Source: gs://[my-bucket]/
Document Name: connecting-vision-and-language-with-video-localized-narratives.pdf
Content:
We propose Video Localized Narratives, a new form of multimodal video
annotations connecting vision and language.
. . .LLM에서 반환된 응답에는 응답과 소스가 모두 포함됩니다. 이렇게 하면 LLM의 응답이 항상 소스에 근거합니다.
말뭉치(Corpus)와 관련없는 질문을 하면 어떻게 될까요?
Query: What is NFC?
....................................................
Response: I cannot determine the answer to that.
....................................................
References:
[REFERENCE #0]
Matching Score: 0.6343
Document Source: gs://genai-solution-devops-asst/corpus
Document Name: annotator-diversity-in-data-practices.pdf
Content:
4.2.1 NLI-based Pretraining. The natural language inference (NLI) task
aims to predict if a given "hypothesis" is supported/entailed by another
input "premise" text.
. . .LLM은 질문이 해당 영역을 벗어나면 "그 대답을 결정할 수 없습니다"라고 응답합니다. 이는 질문이 문맥에 맞지 않을 때 응답하지 않도록 프롬프트를 통해 출력이 조절되기 때문입니다. 이것은 검색된 컨텍스트로 질문에 답할 수 없을 때 환각을 완화하기 위해 가드레일을 구현하는 한 가지 방법입니다. 다음은 LLM과 함께 사용하도록 구성된 프롬프트 템플릿의 지침입니다.
Strictly Use ONLY the following pieces of context to answer the question at the end. Think step-by-step and then answer.
Do not try to make up an answer:
- If the answer to the question cannot be determined from the context alone, say "I cannot determine the answer to that."
- If the context is empty, just say "I do not know the answer to that."지금까지 Vertex AI PaLM API, Matching Engine 및 LangChain을 사용하여 문서에 근거한 QA 시스템을 구축하는 방법을 보여주었습니다.
시작하는 방법
LangChain은 다양한 Generative AI 애플리케이션을 구축할 수 있는 유연하고 편리한 도구입니다. LangChain을 Vertex AI PaLM 기본 모델 및 API와 통합하면 이러한 강력한 모델 위에 애플리케이션을 구축하는 것이 훨씬 더 편리해집니다. 이번 포스팅에서는 Vertex AI PaLM API for Text, Vertex AI Embedding for Text, Vertex AI Matching Engine 및 LangChain을 사용하여 검색기반 생성(retrieval augmented generation) 패턴을 기반으로 QA 애플리케이션을 구현하는 방법을 보여주었습니다.
- GitHub 리포지토리를 복제하고 노트북을 기반으로 자신의 문서로 시도해 보십시오.
- 텍스트 및 임베딩 모델에 대한 Generative AI 지원은 Vertex AI 문서를 참조하세요.
- Vertex AI PaLM API for Text, Embedding API 및 Matching Engine과의 통합에 대해서는 LangChain 설명서를 참조하십시오.
본 글의 원문은 다음에서 확인 가능합니다.
'Google Cloud Blog' 카테고리의 다른 글
| 새로운 진화: BigQuery Data Insights로 데이터 탐색(data exploration)을 최적화하기 (0) | 2024.07.29 |
|---|---|
| Google Cloud에서 생성형(Generative) AI Service 개발을 위한 Code Sample (1) | 2024.03.30 |
| BigQuery 최적화: 테이블 클러스터링(Clustering) (0) | 2023.07.30 |
| Google BigQuery의 인메모리 쿼리 execution (0) | 2023.07.30 |
| BigLake기반으로 Apache Iceberg lakehouse 현대화하기 (0) | 2023.07.16 |


