
tl;dr:
- 클러스터는 뛰어난 성능 및 비용 개선을 제공합니다.
- 클러스터링된 테이블은 로드 속도에 영향을 미칠 수 있습니다.
- 방금 스트리밍, 업데이트 또는 삽입된 데이터는 클러스터링 개선 사항이 즉시 적용되지 않을 수 있습니다. 하지만 — 중단 시간 없이 테이블을 지속적으로 재클러스터링하고 최적화하는 프로세스가 있습니다.
- 클러스터링된 열이 가질 수 있는 값의 수에는 제한이 없습니다. (반면 파티션은 제한이 있습니다)
경고: 이 게시물은 수 테라바이트의 데이터로 실행됩니다. BigQuery 비용 제어를 설정하고 버클을 채우고 침착하게 쿼리를 실행하세요.
왼쪽 쿼리와 오른쪽 쿼리의 큰 차이를 발견할 수 있습니까?
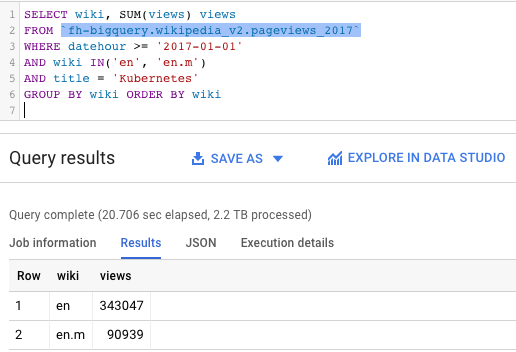 |
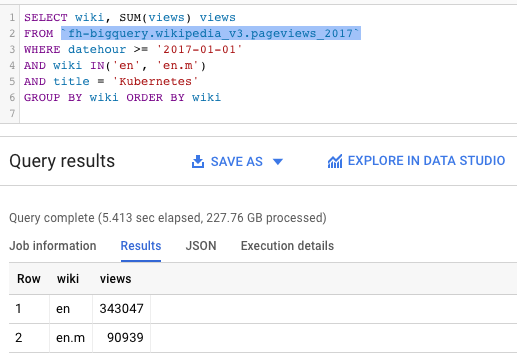 |
거의 동일한 테이블에 대한 동일한 쿼리 — 하나는 클러스터링되고(더 빠르고 효율적입니다.) 다른 하나는 그렇지 않습니다.
우리는 다음을 알 수 있습니다.
- Kubernetes는 2017년 Wikipedia에서 인기 있는 주제였으며 영어 Wikipedia 사이트에서 400,000회 이상의 조회수를 기록했습니다.
- Kubernetes는 기존 데스크톱 사이트보다 모바일 Wikipedia 사이트에서 페이지뷰가 훨씬 적습니다(90k 대 343k).
그러나 정말 흥미로운 점은 다음입니다.
- 왼쪽 쿼리는 20초에 2.2TB를 처리할 수 있었습니다. 인상적이지만 비용이 많이 듭니다.
- 오른쪽의 쿼리는 유사한 테이블을 검토했지만 5.4초 만에 10분의 1의 비용(227GB)으로 결과를 얻었습니다.
비결은 무엇일까요?
클러스터 테이블!
이제 특정 필드별로 데이터를 "정렬"하여 저장하도록 BigQuery에 지시할 수 있습니다. 쿼리가 이러한 필드를 필터링하면 BigQuery는 일치하는 클러스터만 조회합니다. 즉, 더 빠르고 저렴한 결과를 얻을 수 있습니다.
2017년에만 1,900억 이상의 페이지뷰, 3,927개 이상의 Wikipedia 사이트, 540억 이상의 행(연간 2.2TB의 데이터)을 쿼리할 예정입니다.

기존 데이터를 새로 클러스터링된 테이블로 만들기 위해 몇 가지 DDL을 사용할 수 있습니다.
CREATE TABLE `fh-bigquery.wikipedia_v3.pageviews_2017`
PARTITION BY DATE(datehour)
CLUSTER BY wiki, title
OPTIONS(
description="Wikipedia pageviews - partitioned by day, clustered by (wiki, title). Contact https://twitter.com/felipehoffa"
, require_partition_filter=true
)
AS SELECT * FROM `fh-bigquery.wikipedia_v2.pageviews_2017`
WHERE datehour > '1990-01-01' # nag
-- 4724.8s elapsed, 2.20 TB processed
다음 옵션에 유의하십시오.
- CLUSTER BY wiki, title: 사람들이 wiki 열을 사용하여 쿼리할 때마다 BigQuery는 이러한 쿼리를 최적화합니다. 이러한 쿼리는 사용자가 제목과 함께 필터링하는 경우 더욱 최적화됩니다. 사용자가 제목으로만 필터링하는 경우 (wiki의 순서가 중요하므로) 클러스터링의 결과는 정상적으로 작동하지 않습니다.
- require_partition_filter=true: 이 옵션은 사용자에게 항상 쿼리에 날짜 필터링 절을 추가하도록 제약시킵니다.
- 4724.8초 elapsed, 2.20TB processed: 2.2TB의 데이터를 다시 구체화하고 클러스터링하는 데 시간이 좀 걸렸지만 쿼리에서 향후 절감액이 이를 보상합니다. bq export/load 조합을 사용하여 동일한 작업을 무료로 실행할 수 있지만 DDL도 지원합니다. SELECT * FROM 내에서 데이터를 필터링 및 변환하거나 클러스터링 목적으로 더 많은 열을 추가할 수 있습니다.
클러스터링 최적화: 몇 가지 쿼리를 테스트해 보겠습니다.
SELECT * LIMIT 1
SELECT * LIMIT 1은 알려진 BigQuery 안티패턴입니다. 테이블 미리보기를 사용하면 동일한 결과를 무료로 받을 수 있었지만 전체 테이블 스캔에 대해 요금이 부과됩니다. v2 테이블에서 시도해 보겠습니다.
SELECT *
FROM `fh-bigquery.wikipedia_v2.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
LIMIT 1
1.7s elapsed, 180 GB processed180GB가 처리되었지만 적어도 6월만 포함하는 날짜 Partition은 작동했습니다. 그러나 클러스터링된 테이블인 v3에서는 어떨까요?
SELECT *
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
LIMIT 1
1.8s elapsed, 112 MB processedYes!!! 클러스터링된 테이블을 사용하여 이제 SELECT * LIMIT 1을 수행할 수 있으며 데이터의 0.06%만 스캔했습니다.
Base query: 바르셀로나, 영어, 180->10GB
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v2.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
AND wiki LIKE 'en'
AND title = 'Barcelona'
GROUP BY wiki ORDER BY wiki
18.1s elapsed, 180 GB processed쿼리는 v2 테이블에서 180GB의 비용이 발생합니다. 한편 v3 테이블에서는:
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
AND wiki LIKE 'en'
AND title = 'Barcelona'
GROUP BY wiki ORDER BY wiki
3.5s elapsed, 10.3 GB processed클러스터링된 테이블에서 우리는 5%의 비용으로 1/6의 시간에 결과를 얻습니다.
클러스터 순서를 잊지 마세요
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
-- AND wiki = 'en'
AND title = 'Barcelona'
GROUP BY wiki ORDER BY wiki
3.7s elapsed, 114 GB processed클러스터링 전략을 사용하지 않으면(복수 위키를 우선 필터링) 가능한 모든 효율성을 얻지는 못하지만 그래도 이전보다는(180GB) 낫습니다.
더 작은 클러스터, 더 적은 데이터
영어 위키백과에는 알바니아어보다 훨씬 더 많은 데이터가 있습니다. 알바니아어만 볼 때 쿼리가 얼마나 최적화되는지 확인합니다.
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
AND wiki = 'sq'
AND title = 'Barcelona'
GROUP BY wiki ORDER BY wiki
2.6s elapsed, 3.83 GB클러스터는 LIKE 및 REGEX를 사용할 수 있습니다.
r로 시작하는 모든 위키와 Bar.*na와 일치하는 제목을 쿼리해 보겠습니다.
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
AND wiki LIKE 'r%'
AND REGEXP_CONTAINS(title, '^Bar.*na')
GROUP BY wiki ORDER BY wiki
4.8s elapsed, 14.3 GB processed괜찮은 결과입니다. 참고로 클러스터는 LIKE 및 REGEX 으로 접두사를 찾을 때만 효율적입니다.
접미사를 찾는 경우:
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
AND wiki LIKE '%m'
AND REGEXP_CONTAINS(title, '.*celona')
GROUP BY wiki ORDER BY wiki
(5.1s elapsed, 180 GB processed그러면 180GB로 되돌아갑니다. 이 쿼리는 클러스터를 전혀 사용하지 않습니다.
JOIN 및 GROUP BY
이 쿼리는 사용하는 테이블에 관계없이 시간 범위 내의 모든 데이터를 스캔합니다.
SELECT wiki, title, SUM(views) views
FROM `fh-bigquery.wikipedia_v2.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
GROUP BY wiki, title
ORDER BY views DESC
LIMIT 10
64.8s elapsed, 180 GB processed이 결과도 충분히 훌륭합니다. (wiki, title)의 1억 8,500만 조합을 그룹화하고 상위 10개를 선택하고 있습니다. 대부분의 데이터베이스에서 간단한 작업은 아니지만 BigQuery에서는 간단한 작업으로 보입니다. 이것을 클러스터링된 테이블로 개선할 수 있을까요?
SELECT wiki, title, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
GROUP BY wiki, title
ORDER BY views DESC
LIMIT 10
22.1 elapsed, 180 GB processed결과에서 볼 수 있듯이 v3를 사용하면 쿼리 시간이 1/3로 단축됩니다. 데이터가 클러스터링되므로 순위를 매기기 전에 모든 조합을 그룹화하는 데 필요한 셔플링이 훨씬 줄어듭니다.
쿼리 추정기에서 클러스터링에 대한 효과를 어떻게 확인하나요?
BigQuery는 쿼리를 실행하기 전에 각 쿼리가 쿼리할 데이터의 양에 대한 추정치를 제공합니다. 하지만 클러스터링에 대한 개선은 따로 표시되지 않습니다. 대신 클러스터링을 사용하면 추정치가 상한선이며 쿼리는 위에 표시된 것처럼 훨씬 적게 쿼리하게 될 수 있습니다.
정리
- 테이블 클러스터링 — 많은 쿼리를 최적화할 수 있습니다.
- 클러스터링의 주요 비용은 더 긴 로드 시간이지만 그만한 가치가 있습니다.
- 클러스터링할 열과 순서에 대해 합리적인 결정을 내립니다. 사람들이 테이블을 쿼리하는 방법에 대해 생각해 보십시오.
- 업데이트: 이제 클러스터링된 테이블이 GA입니다. — 제한 사항 및 업데이트에 대한 문서를 확인하십시오..
- 업데이트: BigQuery는 테이블을 자동으로 다시 클러스터링합니다. 삽입, 업데이트 및 삭제 후에도 클러스터링의 이점을 얻을 수 있습니다.
'Google Cloud Blog' 카테고리의 다른 글
| Google Cloud에서 생성형(Generative) AI Service 개발을 위한 Code Sample (1) | 2024.03.30 |
|---|---|
| Vertex AI PaLM API 및 LangChain으로 손쉽게 Generative AI 애플리케이션 개발하기 (0) | 2023.08.15 |
| Google BigQuery의 인메모리 쿼리 execution (0) | 2023.07.30 |
| BigLake기반으로 Apache Iceberg lakehouse 현대화하기 (1) | 2023.07.16 |
| 텍스트 데이터 분석을 위한 Vertex AI Embeddings: 대규모 언어모델(LLM) 쉽게 활용하기 (5) | 2023.07.15 |


